คู่มือการเขียน Skill
ในอดีต เมื่อสร้างสรรค์ผลงานด้วย Flova AI หลายคนรู้สึกเหมือนกำลัง “เปิดกล่องสุ่ม” ตะโกนความต้องการใส่กล่องดำ ได้ผลลัพธ์ที่เหมือนกันไปหมด และไม่สามารถควบคุมกระบวนการได้อย่างแม่นยำ เหมือนสายพานการผลิตที่ตายตัว ต้องคอยทำตามขั้นตอนที่ระบบกำหนดไว้ เช่น “เขียนบท - สร้างสตอรี่บอร์ด - สร้างวิดีโอ” ไปทีละขั้นตอน
แต่ครั้งนี้ เราได้นำการเปลี่ยนแปลงครั้งสำคัญมาให้สองประการ:
- “White Box” ที่สมบูรณ์และอิสระในการสร้างสรรค์: เราได้มอบอำนาจการควบคุมเลเยอร์พื้นฐานให้แก่คุณ ไม่อยากผ่านกระบวนการเต็มรูปแบบที่ยุ่งยากใช่ไหม? อยากใส่รูปภาพแล้วทำให้มันเคลื่อนไหวเลยใช่ไหม? หรือแค่อยากปรับแต่ง “Prompt” เท่านั้น? ไม่มีปัญหาเลย! คุณสามารถข้ามขั้นตอนที่ไม่จำเป็นได้ ทำให้การสร้างสรรค์มีความยืดหยุ่นและตรงจุดอย่างยิ่ง
- ประสบการณ์จะกลายเป็น “สินทรัพย์ที่นำกลับมาใช้ใหม่ได้” อย่างแท้จริง: คุณไม่ต้องคอยอธิบายความชอบของคุณให้ AI ฟังใหม่ทุกครั้งที่เริ่มโปรเจกต์ใหม่เหมือนเมื่อก่อนอีกต่อไป ความรู้ระดับมืออาชีพ นิสัยการทำงาน และสุนทรียภาพด้านภาพและเสียงที่คุณร่วมสร้างและสะสมมาจากการใช้งานจริงกับ AI สามารถถูกบันทึกเป็น “เอกสารมาตรฐาน” ได้แล้ว ซึ่งจะเปลี่ยน “เคล็ดลับการสร้างสรรค์ระดับมืออาชีพ” ของคุณให้กลายเป็น “สินทรัพย์ดิจิทัลที่นำกลับมาใช้ใหม่ได้” อย่างแท้จริง และเป็นการฝึกฝนทีมงาน AI เฉพาะตัวที่ยิ่งใช้งานก็ยิ่งรู้ใจคุณมากขึ้น
หัวใจสำคัญที่สนับสนุนสิ่งนี้คือ ระบบ Skill ที่เราเพิ่งเปิดตัว หาก Flova คือ “ฐานการผลิตภาพยนตร์และโทรทัศน์ AI” ที่มีผู้เชี่ยวชาญจากทุกสาขาอาชีพ Skill ก็คือ “แถลงการณ์ของผู้กำกับ + คู่มือการผลิต” ที่คุณส่งให้กับทีมงาน AI นี้
🎞️ โครงสร้างและวัตถุประสงค์ของ Skill: ทำความเข้าใจ Skill จาก “มุมมองของทีมงานกองถ่าย”
มีแท็ก <tag> มากมายในไฟล์ Skill อย่าเพิ่งตกใจไป อันที่จริงแท็กเหล่านี้แสดงถึงงานหลักแต่ละอย่างในทีมงานฝ่ายผลิต Skill ประกอบด้วยส่วนต่างๆ ดังต่อไปนี้ ซึ่งแต่ละส่วนจะสอดคล้องกับแนวทางการทำงานของ Sub-Agent (สำหรับรายละเอียดเกี่ยวกับระบบ โปรดดูที่ [ระบบ Skill - โครงสร้างส่วนประกอบ])
เมื่อระบบโหลด Skill ของคุณ ระบบจะกระจายความต้องการในแท็กเหล่านี้ไปยัง “พนักงาน AI” ที่เกี่ยวข้องโดยอัตนยัติ:
| ป้ายกำกับส่วนใน Skill | คำอธิบายเครื่องมือ Sub-Agent | ตำแหน่งที่สอดคล้องในทีมงานกองถ่าย | งานเฉพาะด้านและจุดควบคุมของคุณ |
|---|---|---|---|
| <Process Planning> | Lead Planner | ผู้ช่วยผู้กำกับ / ผู้กำกับบริหาร | ไม่ก้าวก่ายการสร้างสรรค์งานศิลปะ มุ่งเน้นเพียง “ต้องทำอะไรก่อนและทำอะไรหลัง” โดยจะกำหนดว่าแต่ละแผนกควรเข้าฉากเมื่อใด (ความสัมพันธ์แบบพึ่งพา) และเมื่อใดที่ต้องหยุดเพื่อขอการยืนยันจากผู้กำกับ (ผู้ใช้) |
| <Asset Analysis> | เครื่องมือวิเคราะห์สื่อสร้างสรรค์ด้วย MultiModal Machine Learning | ผู้ช่วยผู้กำกับ / ผู้ช่วยฝ่ายประสานงานสร้างสรรค์ / ผู้ช่วยฝ่ายบท | รับผิดชอบในการถอดรหัสสื่ออ้างอิง (วิดีโอ/เอกสาร/รูปภาพ ฯลฯ) ตัวอย่างเช่น หากคุณใส่คลิปภาพยนตร์คลาสสิก เครื่องมือนี้จะรับผิดชอบการ “วิเคราะห์ภาพยนตร์” สกัดวิถีการเคลื่อนที่ของกล้อง การกระทำทางกายภาพ และแม้แต่ข้อมูลสีภายในภาพได้อย่างแม่นยำ แล้วส่งต่อให้กับแผนกปลายน้ำ |
| <Storyboard Design> | ผู้ออกแบบสตอรี่บอร์ดวิดีโอ | ผู้เขียนบท + ศิลปินสตอรี่บอร์ด | รับผิดชอบการวางแผนบทและช็อต กำหนดว่าใครจะปรากฏตัว ถ่ายอะไรในแต่ละฉาก กำหนดขนาดภาพ และการแสดงออกของการกระทำ ที่นี่ จะไม่จัดการเรื่องการสร้าง (Generation) แต่จะจัดทำเพียง “แผนการถ่ายทำ” เท่านั้น |
| <Media Generation> | เครื่องมือสร้างสื่อ | ผู้กำกับภาพ (DP) | รับผิดชอบการสร้างสรรค์และการผูกสินทรัพย์ (Asset Binding) จำเป็นต้องกำหนดว่าจะใช้โมเดลการสร้างใด (การเลือกเครื่องจักร) และใช้ความละเอียดเท่าใด ซึ่งรวมถึงการคัดเลือกนักแสดงที่เหมาะสมกับบทบาทและการสร้างภาพลักษณ์ที่มองเห็นได้ รับผิดชอบในการผูกภาพอ้างอิงเฉพาะ (รูปลักษณ์นักแสดง) และโทนเสียง (เสียงบรรยาย) เข้ากับช็อตที่เกี่ยวข้องเพื่อให้แน่ใจว่าฉากมีความต่อเนื่องกัน |
| <Prompt Writing> | เครื่องมือปรับแต่ง Prompt (Media Generator) | ผู้ออกแบบงานศิลป์ (PD)/ ผู้ออกแบบเสียง (SD) | เชี่ยวชาญภาษาภาพ แสง และพื้นผิว แปลสุนทรียภาพของคุณให้เครื่องเข้าใจ คุณต้องกำหนด “กฎเกณฑ์ทางภาพ” ไว้ที่นี่ เช่น ใช้ความยาวโฟกัสเท่าใด (50mm/เลนส์มุมกว้าง) ใช้แสงแบบไหน (เช่น แสงคอนทราสต์สูงแบบ Chiaroscuro) กำหนดโทนสี และระบุเทคนิคพิเศษคุณภาพต่ำที่ต้องการคัดออก (negative prompts) |
| <Video Editing> | ผู้ตัดต่อวิดีโอ | ผู้ตัดต่อ | รับผิดชอบการตัดต่อและประกอบภาพหลังการผลิต หลังจากได้รับคลิปทั้งหมดแล้ว จะต้องนำมาต่อกันตามเส้นเวลา (Timeline) ปรับแต่งเสียงให้ตรงกัน และส่งออกเป็นผลงานภาพยนตร์ที่เสร็จสมบูรณ์ในที่สุด |
💡 ตรรกะหลัก:
AI ไม่อ่านทุกอย่างพร้อมกันแล้วทำงานอย่างสะเปะสะปะ แต่มันจะถูก โหลดตามความต้องการ ตัวอย่างเช่น เมื่อถึงขั้นตอนการออกแบบสตอรี่บอร์ด มันจะฟังเพียง <storyboard_designer> เท่านั้น เมื่อถึงขั้นตอนการสร้างวิดีโอ มันจะดูเพียง <media_generator> และ <write_the_prompt> เท่านั้น แต่ละฝ่ายมีหน้าที่ของตนเองและไม่ก้าวก่ายกัน
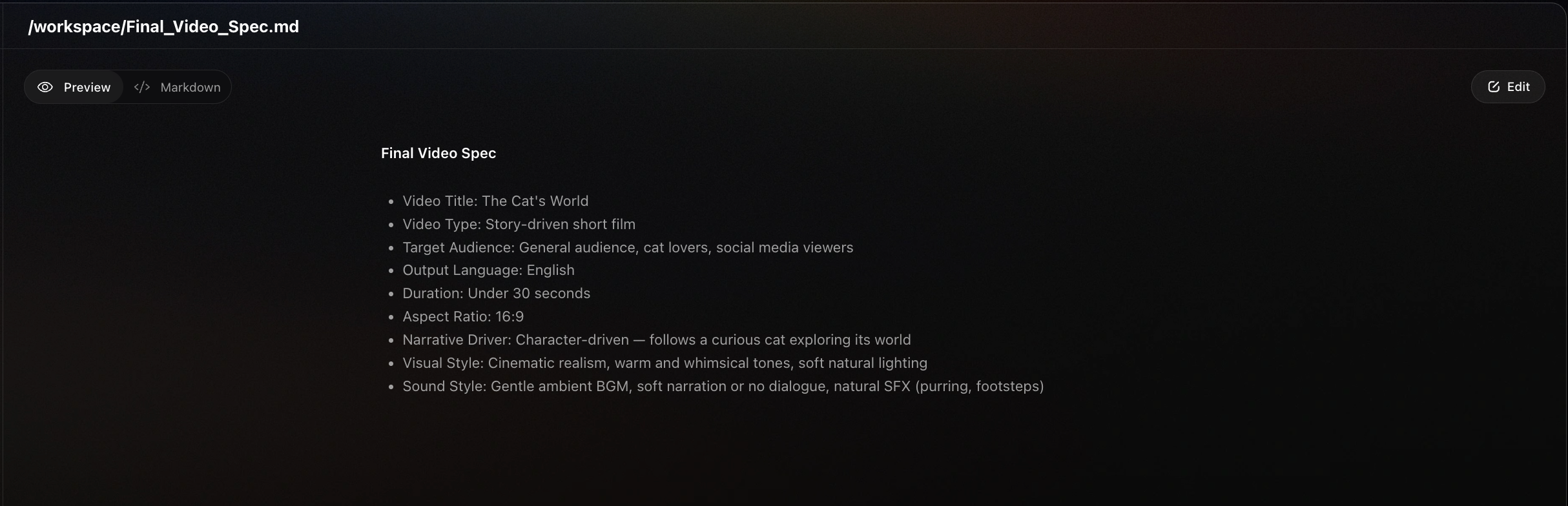
📄 Final_Video_Spec.md และ <text_editor> คืออะไร:
เวิร์กโฟลว์อย่างเป็นทางการประกอบด้วยการจัดทำ “ข้อกำหนดวิดีโอขั้นสุดท้าย” (Final Video Specifications) ซึ่งไม่ได้กล่าวถึงในตารางข้างต้น ส่วนนี้จะเก็บข้อมูลเกี่ยวกับ ชื่อวิดีโอ, ประเภท, อัตราส่วนภาพ, ระยะเวลา, สไตล์ภาพ, ภาษา, ความชอบส่วนตัวเกี่ยวกับโมเดล ฯลฯ ซึ่งเป็น ข้อมูลพื้นฐานในการสร้าง เพื่อให้แน่ใจว่าตลอดกระบวนการสร้างวิดีโอทั้งหมด ผลลัพธ์ที่ได้จะถูกต้องและไม่มีข้อผิดพลาด ดังนั้นเมื่อเขียนเวิร์กโฟลว์ จำเป็นต้องเพิ่มเครื่องมือนี้ก่อนการสร้างสตอรี่บอร์ด แต่จะไม่มีอยู่เมื่อเขียนส่วนอื่นๆ ของ Skill
⬇️เรียนท่านผู้กำกับ หากท่านมีคำบรรยายสไตล์ภาพที่ชัดเจน ท่านสามารถเขียนลงในนี้ได้เลย~⬇️
⚠️ โปรดทราบว่ารูปแบบ </> นั้นเป็นมาตรฐาน:
เมื่อแก้ไข Skill ในรูปแบบ Markdown (คุณอาจเลือกให้ AI จัดการขั้นตอนนี้แทนได้) คุณต้องแน่ใจว่ารูปแบบนั้นถูกต้อง มิฉะนั้น เนื้อหาในส่วนนี้จะใช้การไม่ได้
- ชื่อส่วนต่างๆ ต้องระบุตามตารางข้างต้น
- รูปแบบของส่วนต่างๆ ต้องเขียนตามเทมเพลตอย่างเคร่งครัด ตัวอย่างเช่น เริ่มต้นด้วย <planner> และสิ้นสุดด้วย </planner> ตามลำดับ
✨ Skill นี้จะช่วยประหยัดเวลาและแรงกายของคุณได้มากแค่ไหน?
ในฐานะผู้สร้างมืออาชีพ คุณมี เวิร์กโฟลว์เฉพาะตัว และ มาตรฐานทางสุนทรียภาพ ของคุณเอง มูลค่าที่ยิ่งใหญ่ที่สุดของ ระบบ Skill คือ “การเปลี่ยนประสบการณ์ระดับมืออาชีพของคุณให้เป็นสินทรัพย์”:
- บอกลา AI รสชาติเดียวที่เหมือนกันไปหมด: สุนทรียภาพเริ่มต้นของ AI มักจะธรรมดาและไม่เสถียร คุณสามารถ “สอน” แสง ภาษาภาพ และสีที่คุณชอบผ่าน Skill เพื่อให้ได้ผลลัพธ์ที่หลากหลายและเป็นเอกลักษณ์ตามแบบฉบับของคุณเอง
- สร้าง SOP เฉพาะตัวของคุณ (ซึ่งสามารถนำกลับมาใช้ซ้ำได้): ตัวอย่างเช่น กระบวนการสำหรับวิดีโอรีวิวสินค้า โฆษณารถยนต์ และ MV นั้นแตกต่างกันอย่างสิ้นเชิง เพียงแค่คุณปรับแต่ง “Skill โฆษณารถยนต์” คุณก็สามารถนำไปใช้กับโปรเจกต์ที่คล้ายกันในอนาคตได้ทันทีโดยไม่ต้องเริ่มจากศูนย์ใหม่ทุกครั้ง
- ยืดหยุ่นสูงสุด เริ่มตรงไหนก็ได้ตามใจคุณ: คุณไม่จำเป็นต้องทำตามกระบวนการเต็มรูปแบบตั้งแต่ “เขียนบท -> สร้างภาพ -> ทำภาพเคลื่อนไหว” หากคุณมีภาพที่สร้างจาก Midjourney อยู่แล้ว กระบวนการของคุณก็สามารถเริ่มได้จาก “การทำภาพเคลื่อนไหว” โดยตรง
- เติมเต็มจุดบอดทางวิชาชีพของ AI: AI ไม่เข้าใจศัพท์เฉพาะในบริษัทของคุณหรือข้อห้ามของลูกค้าใช่ไหม? เขียนสิ่งเหล่านั้นลงใน Skill แล้วมันจะกลายเป็นพนักงานเก่าแก่ที่รู้ใจคุณ
🛠️ จะแก้ไข Skill เฉพาะตัวของคุณได้อย่างไร?
หากคุณต้องการปรับแต่งด้วยตัวเอง นี่คือคำแนะนำในการเขียนสำหรับแต่ละส่วน:
‘Process Planning’: กำหนดกระบวนการที่ Agent เรียกใช้เครื่องมือ (ประสานลำดับการทำงานของแผนกต่างๆ)
ผู้สร้างหลายคนรู้สึกว่ากระบวนการเริ่มต้นของ FlovaAI นั้นตายตัวเกินไปและทำให้เสียเวลามาก อันที่จริงแล้ว ทุกอย่างขึ้นอยู่กับ <Process Planning> เป็นผู้ตัดสินใจ
<Process Planning> จำเป็นต้อง อธิบายวัตถุประสงค์ของเครื่องมืออย่างกระชับและชัดเจน โดยไม่ต้องลงรายละเอียดเกี่ยวกับวิธีการปฏิบัติเฉพาะที่นี่ เนื้อหาที่แนะนำให้ระบุ:
- อธิบายกระบวนการสร้างสรรค์อย่างชัดเจน:
- คุณสามารถกำหนดกระบวนการสร้างสรรค์ที่สมบูรณ์ได้: “ขั้นตอนที่ 1: เขียนข้อกำหนดวิดีโอ -> ขั้นตอนที่ 2: เขียนสตอรี่บอร์ด -> ขั้นตอนที่ 3: สร้างรูปภาพ -> ขั้นตอนที่ 4: สร้างวิดีโอ -> ขั้นตอนที่ 5: ตัดต่อและสังเคราะห์”
- สามารถขอเข้าถึงจุดเดียวโดยตรงได้เช่นกัน: “ขั้นตอนที่ 1: สร้างวิดีโอ -> ขั้นตอนที่ 2: ตัดต่อและสังเคราะห์”; “ขั้นตอนที่ 1: สร้างเพลง ไม่ต้องหยุดเพื่อรอการยืนยัน”
- ลำดับและความสัมพันธ์แบบพึ่งพากันก่อนและหลังแท็ก:
- ตัวอย่างเช่น สำหรับการสร้างวิดีโอที่ต้องการเสียงนำทาง (เช่น การลิปซิงค์ใน MV เพลง) จำเป็นต้องระบุให้ชัดเจนว่าต้องเตรียมเสียงให้พร้อมก่อนการสร้างวิดีโอ และเสียงเป็นสื่อสร้างสรรค์ที่จำเป็นสำหรับการสร้างวิดีโอและไม่สามารถข้ามได้
‘Asset Analysis’: บอกความต้องการของคุณแก่โมเดล MultiModal Machine Learning
โมเดลการวิเคราะห์ MultiModal Machine Learning นี้ ใช้เพื่อ ประมวลผล ไฟล์ที่ คุณอัปโหลด เท่านั้น ซึ่งในปัจจุบันรวมถึง: วิดีโอ, รูปภาพ, เสียง และเอกสาร คุณสามารถระบุความเข้าใจของคุณเกี่ยวกับสื่อสร้างสรรค์หรือเกณฑ์ในการแยกส่วนสื่อเหล่านั้นได้
ตัวอย่างเช่น:
- ฉันต้องการเครื่องมือเพื่อวิเคราะห์บทของฉันโดยไม่เปลี่ยนแปลงเนื้อหาหรือจังหวะ
- ฉันต้องการเครื่องมือเพื่อแยกส่วนวิดีโอที่ฉันอัปโหลด แต่จังหวะและระยะเวลาของการแยกสตอรี่บอร์ดวิดีโอต้องเป็นไปตามข้อกำหนด (ดังต่อไปนี้)
‘Storyboard Design’: ให้ AI ถ่ายทำตาม “วิสัยทัศน์ผู้กำกับ” ของคุณ แทนที่จะสร้างแบบสุ่ม
คุณต้องระบุความต้องการในการทำงานแยกกันให้แก่ ผู้ออกแบบตัวละคร, ผู้วางแผนสตอรี่บอร์ด, ผู้ออกแบบเสียง, ผู้ตัดต่อ ตามลำดับ:
- ควรวางแผน “องค์ประกอบสำคัญ” อย่างไร?
- ประธาน (Subject): ตัวละคร (หน้าตาเป็นอย่างไร มีลุคที่แตกต่างกันหรือไม่), โทนเสียงของตัวละคร ฯลฯ
- ฉาก: จำเป็นต้องอธิบายโครงสร้างเชิงพื้นที่และตำแหน่งสำคัญหรือไม่
- ไอเทมสำคัญ (Key Item)
- ......
- ควรวางแผน “สตอรี่บอร์ดวิดีโอ” อย่างไร? (วิดีโอต่างประเภทกันมีความต้องการต่างกัน)
- ภาษาภาพ: ช็อตยาว 15 วินาทีพร้อมการตัดภาพหลายจุด, ช็อตการบรรยายแบบราบเรียบ 6-10 วินาที ฯลฯ
- คำบรรยายช็อต: ควรประกอบด้วยตัวละคร, ฉาก, เนื้อหาเรื่องราว, การโต้ตอบของตัวละคร ฯลฯ
- ......
- ควรวางแผน “เสียง” อย่างไร?
- เพลงประกอบ: หนึ่งชิ้นหรือมากกว่านั้น จะเปลี่ยนตามจังหวะหรือไม่ ฯลฯ
- ผู้บรรยาย/เสียงพากย์: จำเป็นต้องมีผู้บรรยายหรือไม่ กฎเกณฑ์คืออะไร ฯลฯ
- ......
⚠️ โปรดทราบเรื่อง “บทบาท”: “ผู้วางแผนสตอรี่บอร์ดวิดีโอ” รับผิดชอบเพียงการวางแผนบทและช็อตเท่านั้น และไม่จำเป็นต้องเขียนรายละเอียดการสร้างที่นี่ แต่จะจัดทำเพียง “แผนการถ่ายทำ” เท่านั้น
‘Media Generation’: กำหนดโมเดลการสร้างและข้อกำหนดเนื้อหาอ้างอิง
โปรเจกต์ที่ต่างกันต้องการความสามารถที่ต่างกัน คุณต้องการความต่อเนื่องสูงสุดหรือไม่? หรือต้องการคุณภาพของภาพนิ่งที่แข็งแกร่งที่สุด?
ระบุให้ชัดเจนที่นี่: จะใช้โมเดลใดสำหรับรูปภาพ (เช่น Gemini) และโมเดลใดสำหรับวิดีโอ (เช่น Seedance 2.0) คุณยังสามารถบังคับใช้กฎต่อไปนี้ได้: “ ช็อตต่อๆ ไปทั้งหมดต้องอ้างอิงจากภาพตัวละครของช็อตแรกเพื่อให้แน่ใจว่ารูปลักษณ์มีความสม่ำเสมอ ”
⚠️ หมายเหตุ: ข้อจำกัดของความสามารถในการอ้างอิงและความละเอียดที่โมเดลรองรับนั้นขึ้นอยู่กับข้อกำหนดของอินเทอร์เฟซ API อย่างเป็นทางการของโมเดล โปรดดูข้อมูลอินเทอร์เฟซอย่างเป็นทางการของโมเดล หากคุณเลือกที่จะไม่ระบุข้อมูล เช่น โมเดลและความละเอียด Flova จะช่วยจับคู่ตัวเลือกที่เหมาะสมที่สุดให้โดยอัตโนมัติ
รายชื่อเครื่องมือและโมเดลการสร้างภาพของ Flova AI:
| ชื่อเครื่องมืออย่างเป็นทางการ | คำอธิบายภาษาไทย | รายชื่อโมเดลที่รองรับ |
|---|---|---|
TextToImage | ข้อความเป็นรูปภาพ | Seedream 4.5, Nano Banana Pro(Gemini 3 Pro Image), Nano Banana 2(Gemini 3.1 Flash Image), Midjourney V7, GPT Image 1.5, Flux.1 Kontext Pro |
ImageToImage | รูปภาพเป็นรูปภาพ | Seedream 4.5, Nano Banana Pro(Gemini 3 Pro Image), Nano Banana 2(Gemini 3.1 Flash Image), Midjourney V7, GPT Image 1.5, Flux.1 Kontext Pro |
MultiModalToVideo | การอ้างอิงรอบด้าน (วิดีโอ MultiModal Machine Learning) | Seedance 2.0, Seedance 2.0 Fast |
ImagesToVideo | วิดีโอ MultiModal Machine Learning (รูปภาพหลายรูปเป็นวิดีโอ) | Kling 3.0 Omni, Vidu(Q2) |
FirstFrameToVideo | วิดีโอสร้างจากเฟรมแรก | Google Veo3.1 Fast, Sora-2, Sora-2-Pro, Wan2.6, Vidu(Q3-Pro), Seedance 1.5 Pro Audio, Grok Imagine Video, Kling 3.0 Audio, MiniMax Hailuo 2.3 |
VideoInterp | สร้างวิดีโอจากเฟรมเริ่มต้นและเฟรมสิ้นสุด | Google Veo3.1 Fast, Seedance 1.5 Pro Audio, Kling 3.0 Audio, Vidu(Q3-Pro), MiniMax Hailuo 2.3 |
TextToVideo | ข้อความเป็นวิดีโอ | Google Veo3.1 Fast, Sora-2, Wan2.6, Sora-2-Pro, Kling 3.0 Audio, Seedance 1.5 Pro Audio, Seedance 2.0, Seedance 2.0 Fast |
ImageToVideoByAudio | การสร้างวิดีโอที่ขับเคลื่อนด้วยเสียง | OmniHuman1.5 |
lyrics_to_song | การสร้างเพลง | Suno 5, Mureka 8 |
text to narrtion | การสร้างเสียงบรรยาย | ElevenLabs v3, Doubao |
‘Prompt Writing’: การใส่สุนทรียภาพส่วนตัว
นี่คือจุดกำหนดพื้นผิวของภาพ อย่าเขียนแค่ “ภาพสวยๆ” แต่ให้ใส่ ความรู้ระดับมืออาชีพ ของคุณ เช่น เอฟเฟกต์ภาพ, ภาษาภาพ, โดยเฉพาะ ประสบการณ์กับโมเดลต่างๆ เป็นต้น:
- ระบุแยกกันระหว่าง วิธีการเขียน prompt สำหรับการสร้างรูปภาพ และ การสร้างวิดีโอ
- โครงสร้างการเขียน Prompt: เช่น สไตล์ (คำศัพท์เทคนิค) + เนื้อหา (ภาษาธรรมชาติ) + ภาษาภาพ (คำศัพท์เทคนิค) + คำแสดงอารมณ์
- ภาษาภาพ: ระบุการใช้
Over-the-shoulder shot(ช็อตข้ามไหล่),Dutch angle(มุมดัตช์) - แสงและสี: เขียน
deep teal-cyan shadows dominating 90%, zero warm fill(เงาสีน้ำเงินอมเขียวเข้มครอบคลุม 90%, ไม่มีแสงเสริมโทนอุ่น) - เป็นต้น ......
- ตั้งค่าคำ Negative Prompt: เขียนให้ชัดเจนว่า “ไม่มีคำบรรยาย” และ “ไม่มีดนตรี” เพื่อความสะดวกในการตัดต่อหลังการผลิต
- โมเดลบางรุ่นต้องการรูปแบบเฉพาะ คุณสามารถปรึกษาผู้ช่วยอย่างเป็นทางการหรืออ้างอิงเอกสารอินเทอร์เฟซ API อย่างเป็นทางการของโมเดลเพื่อให้แน่ใจว่าการสร้างมีความเสถียร ตัวอย่างเช่น: เมื่ออ้างอิงภาพในโมเดล Kling 3.0 Omni ตัว Prompt ต้องใช้รูปแบบ <<<image 1>>> มิฉะนั้นการอ้างอิงจะล้มเหลว
‘Video Editing’: สิ่งที่ควรทราบในการตัดต่อวิดีโอคืออะไร?
ความสามารถพื้นฐานในการตัดต่อที่ Flova AI รองรับ: การปรับระดับเสียง, การปิดเสียงแทร็ก, การเปลี่ยนความเร็วเสียงและวิดีโอ ฯลฯ คุณสามารถสรุปปัญหาที่พบในกระบวนการสร้างสรรค์ให้เป็นข้อกำหนดและเขียนไว้ที่นี่เพื่อป้องกันไม่ให้ AI ทำผิดพลาดซ้ำเดิมในครั้งหน้า
ตัวอย่างเช่น:
- เมื่อใช้มนุษย์ดิจิทัลในการลิปซิงค์ จะไม่สามารถเปลี่ยนความเร็วของวิดีโอลิปซิงค์ได้
- เมื่อสร้างเนื้อหา MV เพลง ผู้ตัดต่อจำเป็นต้องปิดเสียงแทร็กวิดีโอทั้งหมดและเปิดเฉพาะเสียง BGM เท่านั้นเพื่อหลีกเลี่ยงแทร็กเสียงที่ซ้ำกัน
- ......
🔥 คำถามที่พบบ่อย (FAQ) —— คู่มือการหลีกเลี่ยงข้อผิดพลาด
Q1: ทำไมประสิทธิภาพของโมเดลถึงแย่ลงกะทันหัน แตกต่างจากช่วงสองวันที่ผ่านมาโดยสิ้นเชิง?!
🧠 เปิดเผยตรรกะเบื้องหลัง:
ผู้สร้างหลายคนไม่ทราบว่าการสร้างของโมเดลขนาดใหญ่มีปัญหาเรื่อง “Data Domain Shift” และโมเดลที่ต่างกันก็มีจุดแข็งในด้านสไตล์และเอฟเฟกต์ที่ต่างกัน เอฟเฟกต์ของ prompt สำหรับสไตล์สมจริงและธีมไซไฟจะแตกต่างกันอย่างมากในโมเดลที่ต่างกัน
✅ วิธีปรับปรุง:
คุณสามารถ “ขัดเกลา” ความรู้ระดับมืออาชีพของคำอธิบายภาพสำหรับโมเดลได้
เข้าไปที่ส่วน <Prompt Writing> ของ Skill บรรยายความชอบทางสายตาของคุณโดยใช้ศัพท์เฉพาะทาง (เช่น การถ่ายภาพด้วยฟิล์ม, สีพาสเทล, รายละเอียดที่เข้มข้น, การเปลี่ยนผ่านของแสงและเงา, คอนทราสต์สูง, เลเยอร์ที่เข้มข้น, สุนทรียศาสตร์ที่เลือนลาง, สุนทรียศาสตร์ของแสง, เอฟเฟกต์ lomo เป็นต้น) หรือใน <Media Generation> ให้บังคับว่าการสร้างแต่ละช็อตต้องประกอบด้วยภาพอ้างอิง (matting image) ที่คุณพอใจเพื่อกำหนดสไตล์ให้คงที่
Q2: ฉันมีชุดเวิร์กโฟลว์ระดับมืออาชีพสำหรับบริษัทของฉันเอง ซึ่งแตกต่างจากเวิร์กโฟลว์เริ่มต้นของ Flova ฉันจะแก้ไขได้อย่างไร?
✅ วิธีแก้ไข:
แก้ไขส่วน <Process Planning> คุณสามารถเขียนลำดับขั้นตอนใหม่ทั้งหมดได้ ตัวอย่างเช่น หากกฎของคุณคือ “ต้องสร้างเสียงบรรยายก่อน จากนั้นจึงสร้างวิดีโอตามเวลาของเสียงบรรยาย” คุณสามารถระบุใน Planner ได้ว่า: 1. สร้างเสียง -> 2. วิเคราะห์ความยาวเสียง -> 3. สร้างวิดีโอที่มีความยาวสอดคล้องกัน
Q3: หากสื่อสร้างสรรค์ (รูปภาพหรือวิดีโอ) ที่สร้างโดย AI ไม่สวยงาม จะแก้ไขได้อย่างไร?
✅ วิธีแก้ไข:
เมื่อคุณพบสื่อสร้างสรรค์ที่ไม่ดี เพียงขอให้มันวาดใหม่โดยตรงในช่องโต้ตอบ (“แสงในช็อตที่ 3 มืดเกินไป ทำช็อตนี้ใหม่”) คุณยังสามารถเพิ่มความต้องการเฉพาะใน Final_Video_Spec.md (แผ่นข้อกำหนดสุดท้าย) ของโปรเจกต์เป็นการชั่วคราวได้ ซึ่งจะแทนที่การตั้งค่าเริ่มต้นของ Skill
Q4: กระบวนการนี้ยุ่งยากเกินไป! ฉันแค่ต้องการทำให้รูปภาพเคลื่อนไหว ไม่ต้องการทำเรื่องไร้สาระอย่างการเขียนบทและสตอรี่บอร์ด!
✅ วิธีแก้ไข:
- Flova เวอร์ชันใหม่สามารถรองรับการสร้างสื่อสร้างสรรค์เดี่ยวๆ หรือปรับแต่ง prompt ทีละจุดได้โดยตรงโดยไม่ต้องโหลด Skill ใดๆ
- เมื่อคุณมีการเรียกใช้เครื่องมือมากกว่าหนึ่งอย่าง หรือมีประสบการณ์ในการเขียน prompt อย่างชัดเจน คุณสามารถลดขั้นตอนใน
<planner>ได้! สร้าง Skill ใหม่ที่มีน้ำหนักเบาและลบส่วนที่ไม่ได้ใช้งาน เช่น<Storyboard Design>ออกได้โดยตรง
Q5: ฉันควรทำอย่างไรหาก AI มักจะเข้าใจความรู้ในสาขาอาชีพบางอย่างของฉันผิด (เช่น อุปกรณ์ทางการแพทย์เฉพาะทาง หรือศัพท์เฉพาะเกี่ยวกับตำแหน่งกล้อง)?
✅ วิธีแก้ไข:
สร้าง “อภิธานศัพท์ศัพท์เฉพาะ” ให้กับมันใน <Storyboard Design> หรือ <Prompt Writing> ตัวอย่างเช่น เขียนว่า: "หมายเหตุ: เมื่อฉันพูดถึง 『push shot』 โปรดแปลเป็น 『Slow dolly shot in』 ใน prompt และห้ามใช้การซูมโดยเด็ดขาด". ป้อนความรู้ระดับมืออาชีพให้มัน แล้วมันจะไม่ใช่มือสมัครเล่นอีกต่อไป
Q6: ฉันควรทำอย่างไรหากโมเดลที่ฉันต้องการใช้ (เช่น โมเดลอนิเมะเฉพาะ) ไม่รวมอยู่ในคำแนะนำ Skill อย่างเป็นทางการ?
✅ วิธีเปลี่ยน:
เพียงระบุชื่อและความละเอียดของโมเดลที่ต้องการเรียกใช้ในส่วน <media_generator> (ดูรายชื่อด้านบน) ตราบใดที่เป็นพูลโมเดลที่แพลตฟอร์มรองรับ คุณสามารถสลับได้อย่างอิสระ โมเดล Flova ที่ฉันต้องการใช้นั้นไม่มีให้เลือกใช่หรือไม่? ยินดีต้อนรับสู่การส่งรายชื่อโมเดลที่คุณชื่นชอบไปยังฝ่ายบริการลูกค้าอย่างเป็นทางการ!
Q7: Skill เริ่มต้นอย่างเป็นทางการมีคำศัพท์มากเกินไป ฉันไม่เข้าใจและไม่อยากอ่าน ฉันควรทำอย่างไร?
✅ วิธีแก้ไข: เราขอแนะนำว่าคุณควรเลือก Skill ที่ใกล้เคียงกับเวิร์กโฟลว์ของคุณมากที่สุดและทำการแก้ไขเฉพาะจุดตาม Skill อย่างเป็นทางการ หากคุณมีคำถามหรือพบปัญหาที่ Skill ไม่ทำงาน สามารถแบ่งปันในกลุ่มผู้ใช้หลักของเราได้ และทีมงานมืออาชีพของเราจะตอบคำถามของคุณ
ในอนาคต Flova มีแผนจะเปิดตัวเครื่องมือ AI ที่ออกแบบมาเพื่อช่วยในการเขียน Skill โดยเฉพาะ เพียงแค่อัปโหลดประสบการณ์เวิร์กโฟลว์ที่ผ่านมาของคุณ แล้ว Flova จะช่วยคุณแปลงเป็นเอกสาร Skill ในช่วงการทดสอบภายในนี้ คุณยังสามารถแบ่งปันประสบการณ์การแปลงเวิร์กโฟลว์เป็น Skill กับเราเพื่อช่วยให้เราเปิดตัวเครื่องมือ Skill Agent ที่เป็นมืออาชีพยิ่งขึ้น!
💬 คำถามของคุณยังไม่ได้รับคำตอบใช่หรือไม่?
อย่าลังเลที่จะติดต่อทีมปฏิบัติการอย่างเป็นทางการเพื่อเข้ากลุ่ม นำลิงก์ผลงานและคำถามของคุณมาพูดคุยกับเหล่านักสร้างสรรค์ระดับแนวหน้าเกี่ยวกับ ข้อมูลเชิงลึกในฐานะผู้กำกับยุค AI ของคุณเอง!
ข้อมูลข้างต้นเป็นเพียงพื้นฐานการเขียนเวิร์กโฟลว์เริ่มต้นอย่างเป็นทางการของ Flova AI ซึ่งมีจุดประสงค์เพื่อใช้เป็นจุดเริ่มต้น เราหวังว่าจะเห็นเหล่านักสร้างสรรค์นำสุนทรียภาพและความรู้ระดับมืออาชีพของคุณมาใส่ไว้ใน Skill เพื่อสร้างสรรค์และปลดล็อกการเล่นที่พิเศษและน่าทึ่งยิ่งขึ้น!
อัปเดตล่าสุดเมื่อ